Using Natural Language Processing in competition cases

Share
In competition proceedings, dozens of hypotheses require testing, but the data to analyse these questions is often not feasibly available. Natural Language Processing is changing that. Rashid Muhamedrahimov[1] showcases how NLP is a powerful and exciting area of data science that allows us to extract information from textual sources systematically, building datasets that were prohibitively costly to analyse with traditional techniques, or impractically time consuming.
The views expressed in this article are the views of the authors only and do not necessarily represent the views of Compass Lexecon, its management, its subsidiaries, its affiliates, its employees or its clients.
Introduction
In competition proceedings, there are often dozens of hypotheses that require testing. Some are relatively straightforward, such as testing whether the market share of a firm is above a certain threshold. Some are less so – for example, we may want to test whether merging parties are close competitors; or we may want to understand the extent to which customers of the merging parties support the proposed merger.
In many cases, the data needed to analyse such questions is readily available – either held by the parties involved in a proceeding, or acquired from third party sources. For example, it is common to obtain transaction data and use it to calculate different parties’ market shares, or to assess closeness of competition by calculating diversion ratios based on historical sales data.
It is much more difficult to measure “qualitative” aspects, such as whether firms have overlapping innovation pipelines. In these cases, practitioners and authorities often face a barrier: the data required to test such hypotheses is not readily available in simple standardised formats. The problem is not that data doesn’t exist at all - but that it is only available from sources that make it much harder to process and analyse. For example, information is often embedded in various textual documents held by either of the merging parties or in articles by third-party sources.
Traditionally these sources have been very hard to use. It has been impractical to extract useful information, requiring extensive manual review of internal documents to compile data on issues of interest. Sometimes the scale of the task makes it impossible: to understand whether customers think a product is “high quality”, for instance, might require reading millions of online reviews. Even then, consistency would be hard to ensure and demonstrate.
Natural Language Processing (NLP) is a set of modern techniques from data science that can overcome the limitations of manual review. Widely used by businesses and researchers, it has the benefit of being more systematic (i.e., there is an empirical methodology that can be validated) and is substantially more straightforward to scale – whether there are 100 documents or 1 million, the same tools can be applied. This article outlines two recent case studies where Compass Lexecon data scientists used NLP to provide datasets for analysis that would not have been practical otherwise. But NLP’s potential extends much further. It is a powerful toolkit that could be used to answer a wide range of previously difficult questions in competition cases.
Case 1: Analysing closeness of competition using news articles
One application of NLP is analysing closeness of competition of merging parties in situations where data would not have been available using traditional techniques.
In certain cases – such as, when analysing providers of consumer goods – one can measure this reasonably straightforwardly using metrics like diversion ratios calculated using sales data, or by aggregating web browsing behaviour.[2]
In other cases, the metrics of closeness are less straightforward to analyse. For example, in some industries such as professional services or technology, one potential measure of closeness is the extent to which professional staff move between different firms. In industries where staff are the key determinants of the services offered and competitive position of the firm, the more that a pair of firms have staff moving between them, the stronger the indication that those firms are closer competitors. The data required to measure such movement is often not readily available. In principle, the merging parties could hold data on where their staff joined from and where they went to (and indeed, with the development of “people intelligence” functions in firms, this is becoming easier). However, in order to build a complete picture such data would need to be obtained from all firms in the market of interest. Given there could be dozens of non-merging party firms, this would be logistically impossible.
Instead, in a recent case Compass Lexecon data scientists extracted data from industry publications.[3] These publications often contain sections of news which discuss important people moves, with information about the person moving, the origin firm, and the destination firm. The challenge, however, is that such data isn’t actually “data” in the traditional sense: it is “natural language” – written prose, not structured in a way that would enable a computer to easily understand which aspects of the text we care about.
Figure 1: Illustrative example of news in an industry publication

However, using the NLP toolkit it is possible to convert natural language into something more systematic that we can analyse critically. This is done in two steps.
The first is named entity recognition (NER). For humans, it is easy to tell whether a word refers to a firm or a person (or something else). It is intuitive that Johnson is a surname, but Johnson and Johnson is a company.
For computer programs, this is far from trivial – they do not have any human intuition built into them. NLP techniques overcome this lack of intuition by leveraging algorithms trained on billions of observations. In the “training” phase, an algorithm is fed a large set of labelled observations, which effectively is a large body of text where all relevant entities are identified and categorised (thus determining whether that entity is a company, person, country, and so on). During its training, the algorithm attempts to guess the entity label, and once informed whether that guess was successful or not, it updates itself to improve the accuracy of future guesses. Once its training is complete, the algorithm can use the information it has stored to make a best guess on new text with a high degree of accuracy.
Unlike traditional “keyword” techniques, we do not have to give the algorithm a list of rules to apply in advance (for example, ‘if an entity has LTD in the name it is a company’). Rather, the algorithm effectively generates these rules itself based on the training data, learning how specific words and their context determine labels. For example, consider the sentence “Apple is looking at buying UK startup for $1 billion”. In such a sentence, “Apple” is clearly referring to the tech firm and not the fruit – and a good NER model would be able to know this, given the context of the sentence.
Considering the closeness of competition analysis, the following (fictional) article heading and summary would result in the following named entity labels.
The labels themselves are already a useful starting point, as they tell us the companies and the individuals involved. However, this in itself may hide an asymmetry – if all the moves between firms X and Y are in one direction, this is likely not indicative that they are close competitors. Therefore, in practice it is useful to go one step further and identify the direction of the movement.
Figure 2: Illustrative example of algorithmic labelling

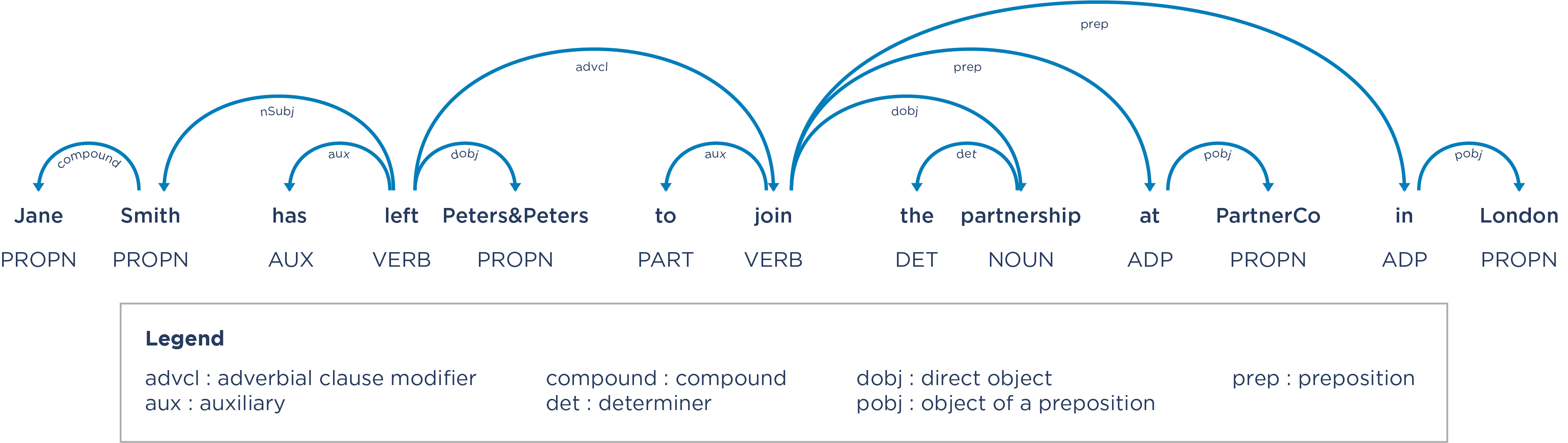
This is the second step of the approach deployed by Compass Lexecon: dependency parsing. This technique is used to encode the linguistic structure of sentences within the articles. It identifies the parts of speech – for instance, whether words are nouns or verbs, and the dependencies between them (such as identifying which words are the subject and object of the sentences, and how the key verbs relate to them).
Figure 3: Output from a dependency parsing algorithm
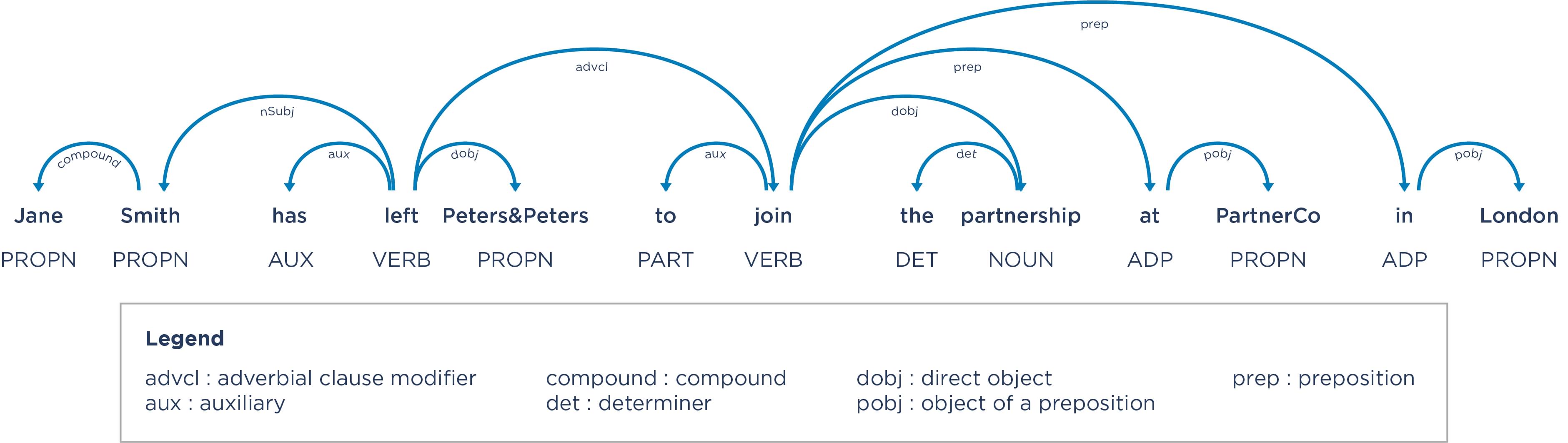
Once we know the various parts of speech and dependencies, and we combine this with the named entity recognition, we can then apply a set of rules that extracts the data that we require to analyse closeness of competition. For example, we can encode patterns such as the one above: person (has left/departed/has quit, etc) origin firm to join destination firm. Another pattern might be destination firm (acquires/has hired/has nabbed, etc) person from destination firm. Doing this systematically across all articles in a sample and aggregating the results gives us the rich dataset we need.
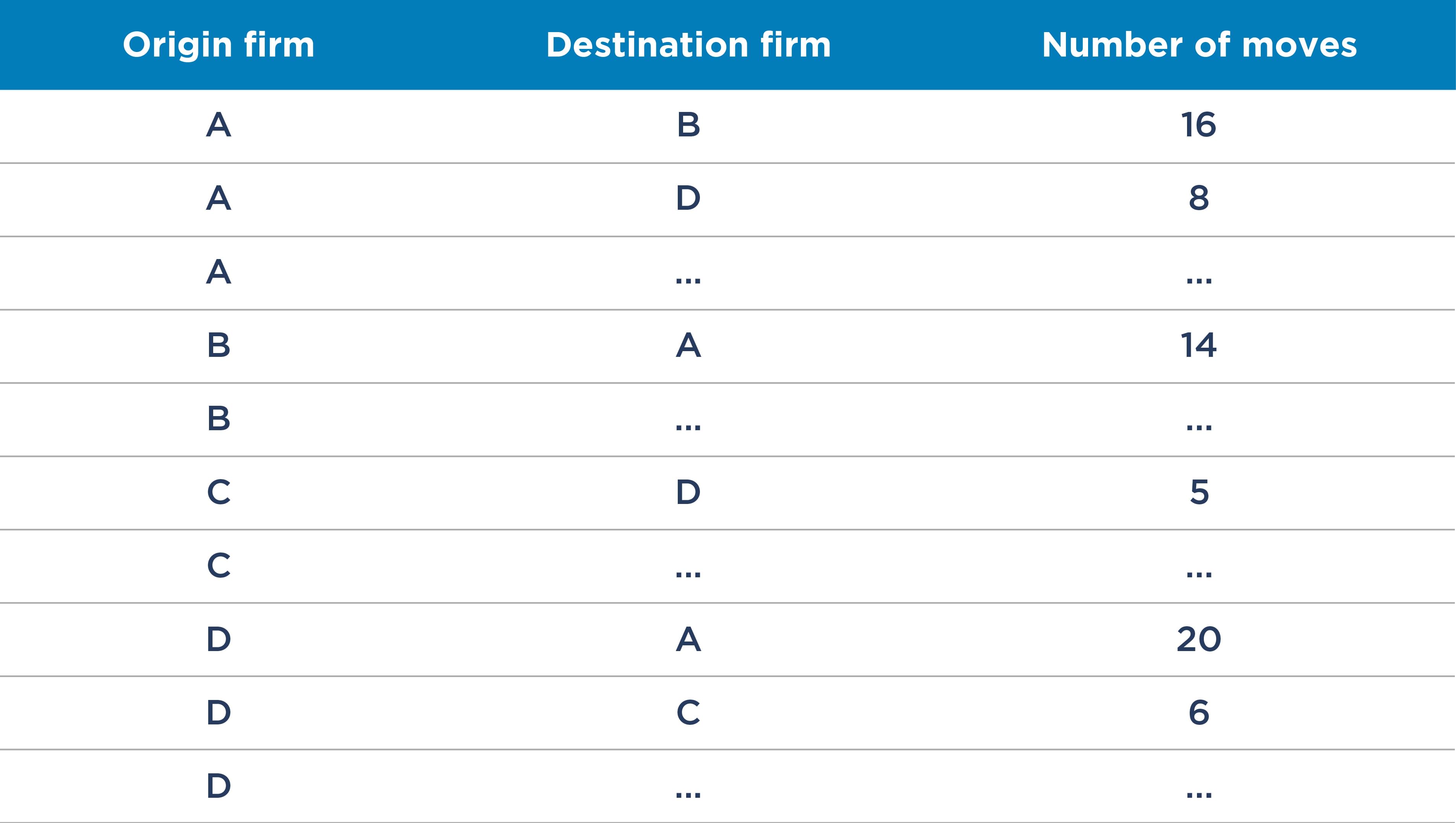
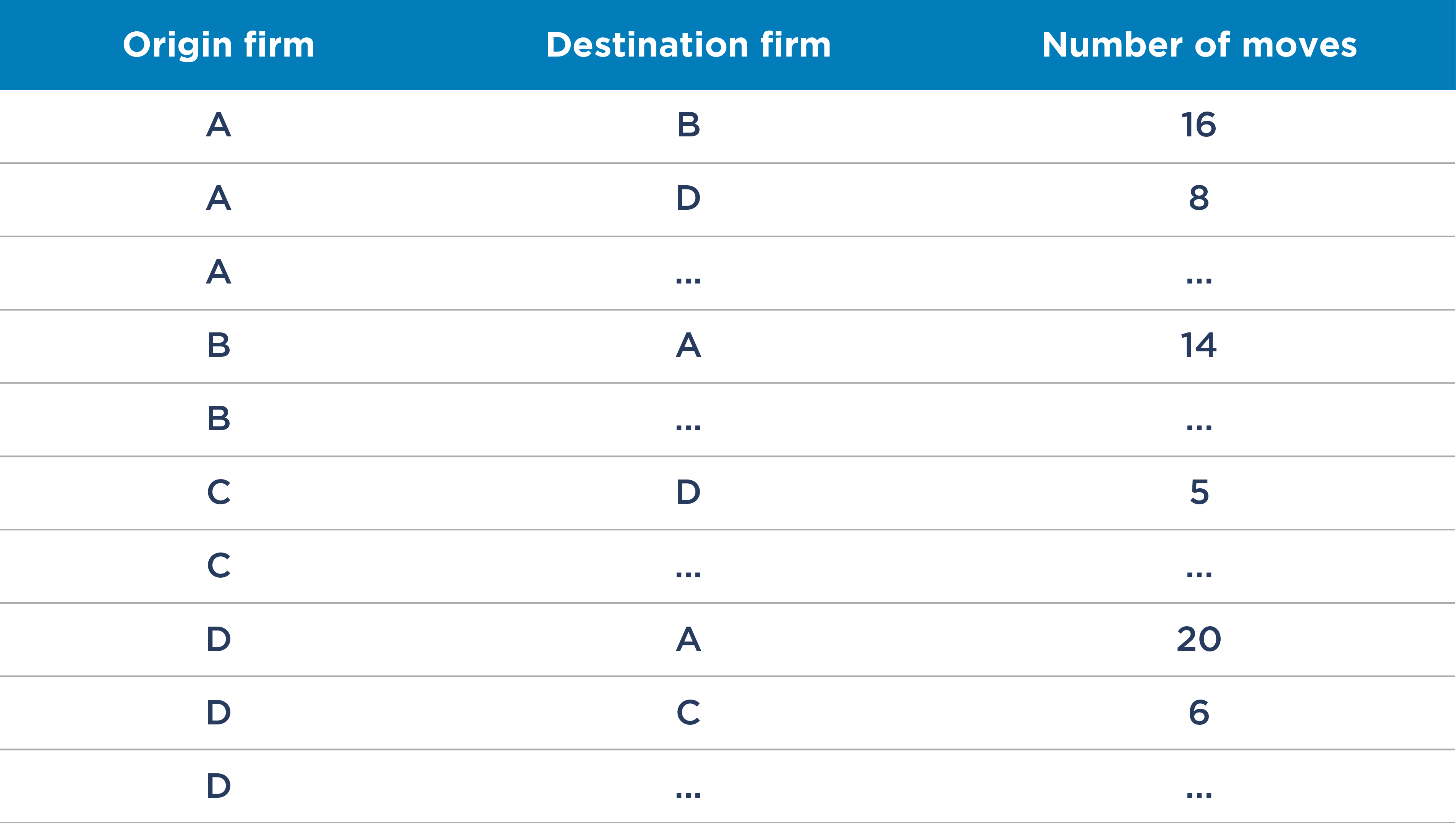
Table 1: Example closeness of competition data based on staff moves
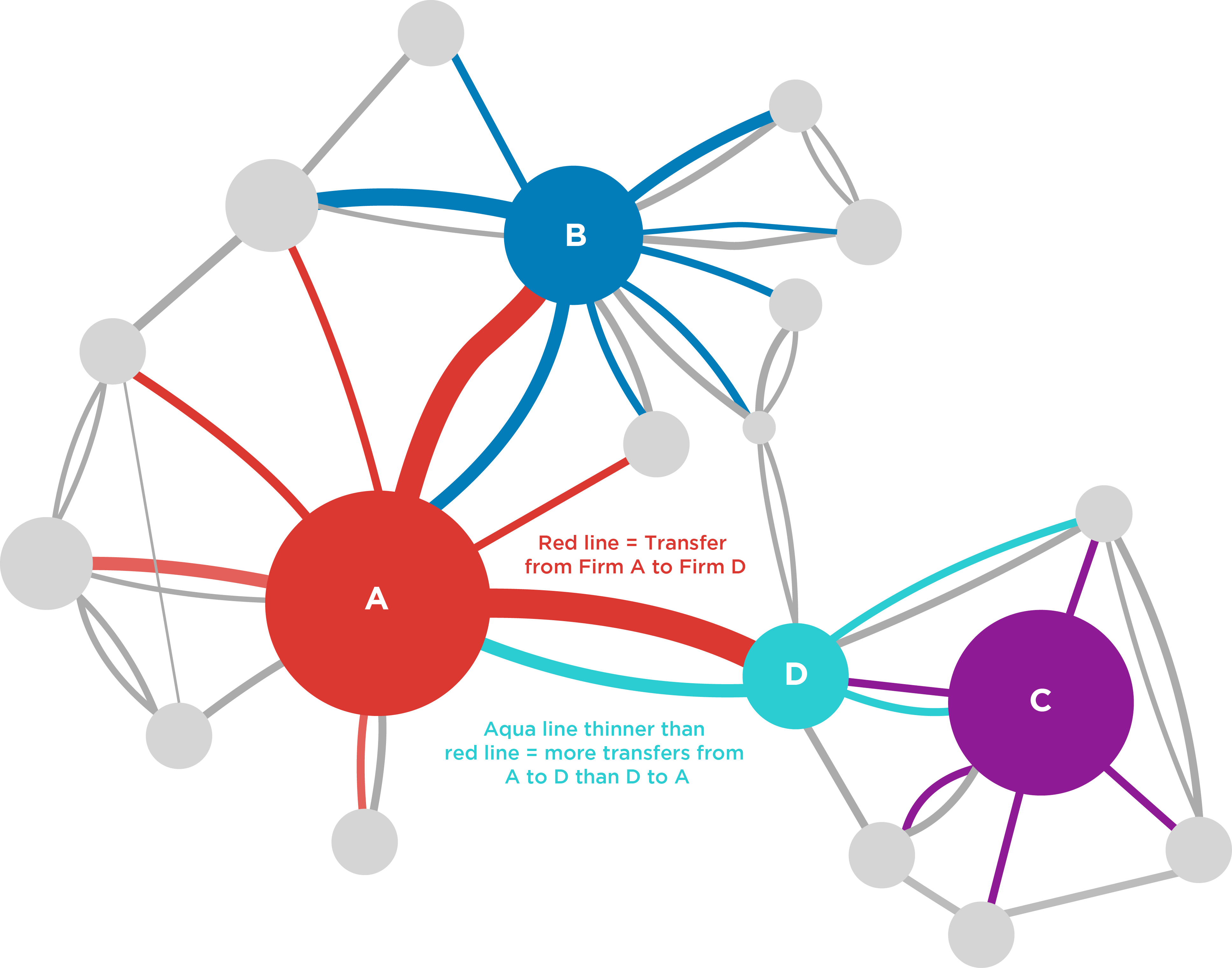
Additionally, as was done by Compass Lexecon on a recent EC merger, one can visualise the transfers in a Sankey[5] or network diagram to develop further insights. For example, if one were to only look at the size of the firms involved, a merger between firm A and firm C might be considered the most problematic.[6] However, in this example there are no direct staff transfers between A and C – rather they are only indirectly close in the sense that both have staff transfers to and from firm D.With such data, one can do several things to quantity and analyse how close certain competitors are. For example, for each firm one could calculate “diversion ratios”,[4] similar to how one would apply them to customer diversion.
Figure 4: Example of closeness of competition using staff transfers
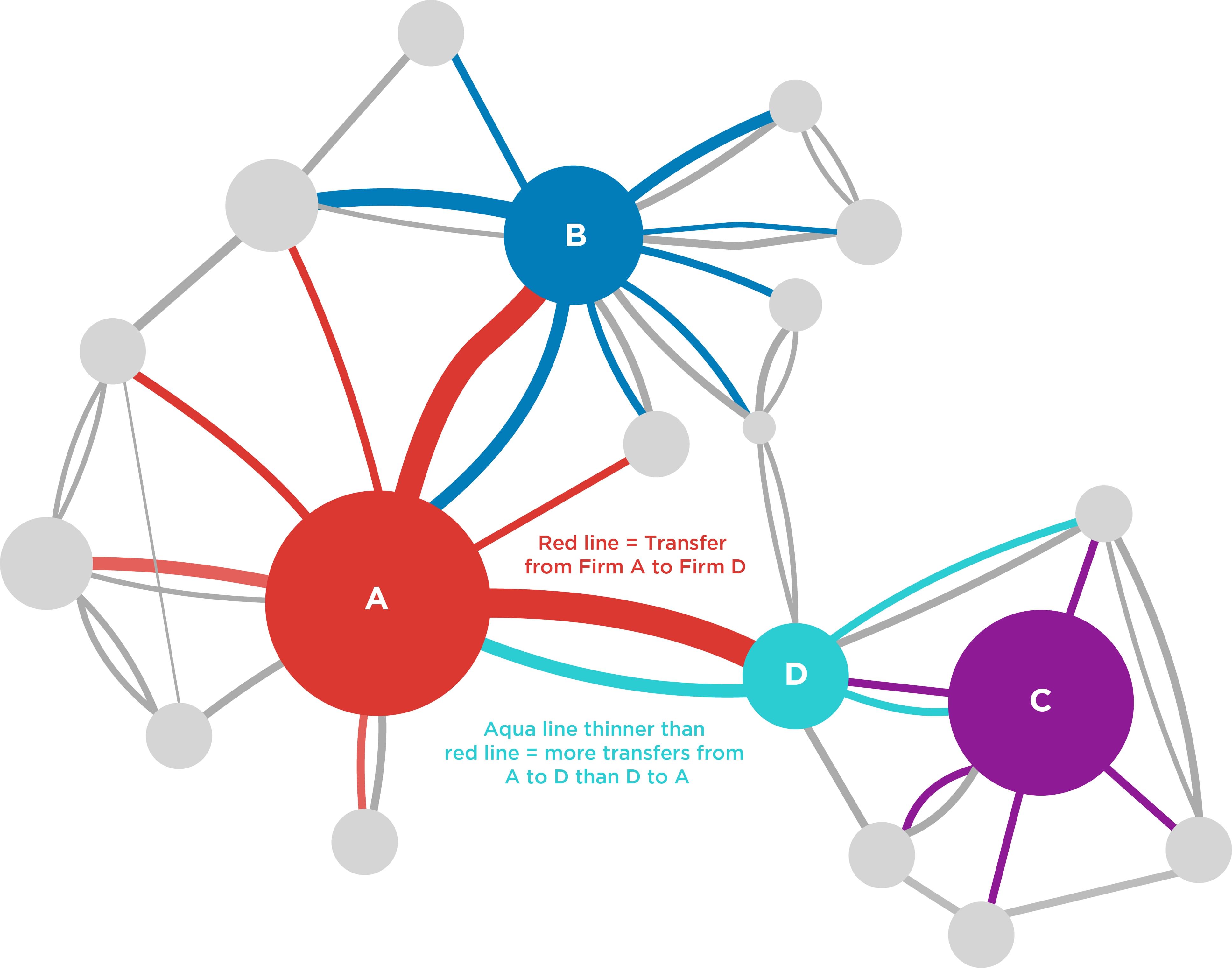
Note: Line between two firms (circles) indicates staff movements. The colour of the line indicates the origin firm, and the width is proportional to the number of staff moves.
On the other hand, using simple size or market share metrics might suggest that a merger between firms A and D is not necessarily problematic. However, conducting the NLP analysis would provide evidence that the firms are potentially close competitors, with a large number of staff moving from A to D, as well as a (relative to the size of D) large number of staff moving from D to A.
Conducting such an analysis would also reveal that in a world where A and D were to merge, the combined A/D firm would be close competitors both with B (as A was before) but now also with C, to which A was not a close competitor previously.
Case study 2: Analysing industry views on a merger
In another recent case, we used NLP techniques to address a different question: to analyse a proposed theory of harm. Compass Lexecon economists needed to determine whether market participants expected the acquired firm’s product to succeed in the market, and whether their expectations had changed since the announcement of the proposed transaction.
A direct approach would ask (through surveys or some other method) the stakeholders potentially affected. EC market investigations apply a similar approach. However, it comes with some difficulties:
- First, it might not be feasible to identify a representative list of relevant customers and competitors to ask;
- Second, the data collection process can be costly and burdensome, making it disproportionate (and practically, not cost effective) for single questions;
- Third, such an approach is “one shot”: once a specific set of questions has been asked, asking further questions is rarely feasible; and
- Finally, for historical questions (e.g., as to whether views have changed) a survey asking about previous changes in perception may be subject to various biases.
However, by using NLP it is possible to analyse this issue systematically and without surveys, while overcoming these obstacles. By extracting a set of relevant news articles – which include quotations from industry commentators, competitors and customers – one can systematically analyse those views and categorise them as positive, negative or neutral. From that data, one can obtain robust evidence on stakeholders’ views.
This NLP task is called sentiment analysis. Despite its name, the technique is a general one that allows classification of statements into various categories (not just positive or negative sentiments). Doing so requires a language model – a type of statistical model that can help computers understand how different words relate to different “real” phenomena; and how context can affect their meaning.[7]
A sentiment analysis model assigns a label – in this case, “positive”, “neutral” or “negative” – to each article or quotation analysed. In simple cases this can seem trivial: a phrase such as “I think this product is a great addition to the market” can easily be identified as positive by the use of “great”. There are many such cases where just looking for specific keywords or assigning values to individual keywords would be sufficient – as is done in traditional NLP approaches.
In other cases, however, correctly assigning a label to text can be more complicated, such that keyword analysis would reach the wrong conclusion. Consider the example sentence: “However, several customers consider that the acquisition would be detrimental to the success of AcquiredCo’s product offering, as it could restrict its useful interoperability”. Intuitively, words such as “detrimental” and “restrict” imply negative sentiment, and considered in isolation, words such as “success” and “interoperability” imply positive sentiment. In such a case, it is unlikely a simple model based only on keywords would do very well at predicting the overall sentiment of the phrase, even though it is trivial for us to recognise that the sentence is negative.
For this analysis, we need to use more sophisticated “deep learning” models that take account of context. This is a broad category of models responsible for much of the success of language processing over the last decade. There are many such models in existence, some of which make it into the news with sensationalist headlines.[8] While they can be applied to a range of tasks, they are extremely useful for exercises such as automatic tagging of sentiment because they are very good at “understanding” context. They do that by algorithmically unpicking how the various words in a sentence connect to one another (analogously to how a human reader would) and come up with a label for whether the model predicts whether the overall sentiment expressed is positive or negative.[9]
Describing exactly how language models understand context is far from straightforward. Models can have hundreds of millions of individual parameters that interact in order to analyse language. To illustrate this, the following chart shows an example of how one subcomponent of a model (a so-called “layer”) draws connections between different words in a sentence.
Figure 5: Demonstration of one component of a deep learning language model[10]
[video width="306" height="786" mp4="https://storage.googleapis.com/compass-lexecon-assets/legacy/2022/03/NLP_Figure_5_AdobeCreativeCloudExpress.mp4"][/video]
Before conducting sentiment analysis, one needs to choose which model to use. While many modern deep learning models are designed with a wide range of tasks in mind, different models are better suited for different uses. This is because different models are trained on different datasets, have different architectures, and so may perform differently depending on the use case. For example, a model that has been trained primarily using social media data might be less relevant to certain uses than a model that has been trained and optimised on legal texts. With a correctly selected model, we have a powerful tool that we can ask many questions of, and which we can scale to very large datasets.[11]
On this case, Compass Lexecon analysed a set of news articles from a variety of sources over several years, containing commentary and opinions of industry observers, customers and competitors. The most relevant model was the RoBERTa[12] model developed by researchers at Facebook. This model was trained on a large body of text data with the goal of performing reliable binary sentiment analysis for English-language text, and was fine-tuned and evaluated on 15 different datasets from diverse text sources, such as news articles and Wikipedia posts.
For each of these relevant quotations and statements, we used the model to classify the sentiment, and effectively demonstrated that the perceived success of the merging parties’ product had increased since the announcement of the merger.
Sentiment analysis, using NLP, offers several benefits compared with a more traditional approach, such as reviewing quotations manually. The first is scale – while it would be possible to have humans classify hundreds of articles in a feasible time frame, this would become very burdensome as the number of articles reaches the thousands or tens of thousands, as is often the case with similar exercises analysing social media posts or product reviews.
The second benefit is that the transparency of its methodology allows scrutiny. Sentiment analysis by humans will inevitably involve individual idiosyncrasies and errors. An authority may not trust the analysis, either because it finds errors or because it cannot meaningfully verify that the analysis was conducted reliably (even if it is in fact accurate). In contrast, the superiority of statistical sentiment analysis is not that its results will be free of error or bias (although they often will be), but that it provides a clear, explicit methodology, as well as testable assumptions. That allows an authority to assess the risk of error for itself, fostering trust.
That is not to say that this process is mechanical. Evaluating the model’s output is still fundamentally a human task that requires critical assessment of the model’s outputs and an understanding of how different modelling and data processing decisions can affect these. Similarly, the process of preparing the code and programs to run such models at the level required for submissions to competition authorities is far from trivial, requiring deep programming skills and expertise in NLP.
Conclusion
NLP is a powerful and exciting area of data science, allowing us to extract systematic information from textual sources that would otherwise be prohibitively costly to analyse, or impractically time consuming. It is also a very dynamic field – the set of techniques and models is growing and constantly improving.
Modern NLP techniques have a wide range of potential applications in competition cases. Even if we limit ourselves to the three techniques described above – named entity recognition, dependency parsing and sentiment analysis – they have various valuable applications in competition. When we consider the wider universe of NLP techniques, the set of applications becomes very large indeed. These can include:
a. Market definition or closeness of competition: Using product descriptions, product reviews or social media posts, NLP can allow measurement of product similarity, and can allow users to classify products (for example into clusters) for the purpose of market definition or measuring closeness of competition.
b. Understanding public responses to a merger or to events: As discussed above, using a binary classification (for example, into positive or negative sentiment), it is possible to categorise news articles and other sources of information to understand public sentiment about a proposed merger. This can be augmented by breaking down how sentiment varies across different categories of commentators (e.g., by geography or political leaning). Equally, it is possible to measure sentiment (as well as the intensity of sentiment) in response to events such as Fast-Moving Consumer Goods product recalls, social network outages or ESG/CSR failures by firms. Such applications would allow a robust quantification of variables such as reputational damage.
c. Expected future innovation and competition: By analysing parties’ press releases or internal documents, one could measure the extent to which certain outcomes and developments are seen as more or less likely in the future.
d. Efficient analysis of internal documents: Often, valuable information about a firm’s competitive position is “hidden” in a vast number of internal documents, for example in tender documents listing participating competitors. Using document data extraction along with NLP techniques, it is possible to parse large numbers of documents and extract information on whether competitors were present in specific tenders.
Of course, as with any novel technique, it must be applied with care. Like any empirical method, it must be carried out correctly, and its limitations must be well understood. When done correctly in conjunction with other evidence, it can provide an incredibly powerful tool with which we can analyse new types of evidence, and help reveal a richer and more accurate picture of competition in an industry.
Read all the articles from the Analysis
[1] The views expressed in this article are the views of the author only and do not necessarily represent the views of Compass Lexecon, its management, its subsidiaries, its affiliates, its employees, or its clients. This article discusses analytic techniques applied by Compass Lexecon data scientists and economists in recent cases. For confidentiality, we do not discuss the specific parties, industries, or facts of those cases.
[2] For example, one could analyse data from online retail to see what products users ultimately buy after browsing some other set of products.
[3] This discussion is based on work done by Compass Lexecon on the Aon/Willis Tower Watson merger (public version of the decision is still pending).
[4] In this case, one could calculate the percentage of staff leaving Firm A that joined Firm B, Firm C, and so on.
[5] This is a type of chart that allows visualisation of “flows”.
[6] Generally, one would consider turnover or quantity of sales for analysis of market shares, but for this illustrative example we do not need to be specific about this point, and can consider size to mean either sales or turnover, or the number of staff.
[7] This is the same category of technology that is contained in modern “digital assistants”, which need to convert human spoken language (e.g., “what is the weather today?”) into a set of systematic data points that provide instructions (in this case, look up the most recent temperature and rainfall in a specific database).
[8] For example, “A robot wrote this entire article. Are you scared yet, human?”, 8 September 2020. Available at (accessed on 15 March 2022): https://www.theguardian.com/commentisfree/2020/sep/08/robot-wrote-this-article-gpt-3
[9] These models are typically trained on some very large bodies of text by asking them to do tasks such as next-word prediction and iterating through model parameters until they get the prediction correct. Following this “general” training, they are then “fine-tuned” to perform well at specific tasks, such as sentiment analysis. The general training in particular requires vast quantities of data and computing power.
[10] This is a visualisation of so-called “attention” – very broadly, it shows how one component of the language model (here, BERT) contextualises each word by drawing connections to other words that are important in its context. “[CLS]” and “[SEP]” are special characters that the model uses to understand what is the start and end of the sentence. This diagram is made with BertViz (https://aclanthology.org/P19-3007.pdf).
[11] There is also more technical question of whether to use something “off the shelf” – for example by using models developed in academia or in the private sector and made open source – or whether to go through the process of fine tuning a specific model.
[12] “RoBERTa: An optimized method for pretraining self-supervised NLP systems”, 29 July 2019. Available at (accessed on 15 March 2022) https://ai.facebook.com/blog/roberta-an-optimized-method-for-pretraining-self-supervised-nlp-systems/
Related insights
-

Article • 01 Feb 2022
Game, Set and Fuzzy match

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}