Shift Happens: Navigating the Big Data Paradigm

Share
Introduction
In this article, Enrico Alemani, Arpita Pattanaik, Tristan Salmon, Ethan Soo [1] discuss the challenges that increasing volumes of data bring to our clients and regulators. They illustrate how Compass Lexecon is rapidly able to transform significant amounts of raw data into actionable insights by leveraging innovative solutions to deal with big data.
What has shifted?
The amount of data being handled by our clients and requested by regulators is ever increasing. In this article, the data science team discusses how to deal with increasingly large data in the context of the daily work of economic consultants.
More data than ever is being generated in an increasingly digital and measured world. This comes from transactions, messages, image data, social network information, app usage, etc. With the prevalence of smartphones and digital devices in virtually every walk of life, each of us is effectively now a walking data generator. As an illustration, Google processes over 99,000 searches every second, WhatsApp transmits 1.2 million messages a second and 3.9 million emails are sent and received every second (most likely in the context of merger proceedings…). This growth is not expected to stabilise any time soon. For instance, the volume of data generated worldwide was 32 times greater in 2020 than in 2010 according to data from Statista.
Figure 1: Volume of data/information created, captured, copied, and consumed worldwide from 2010 to 2025 (2021-2025 forecasted), in zettabytes (1 zettabyte = 1 bn Terabytes)
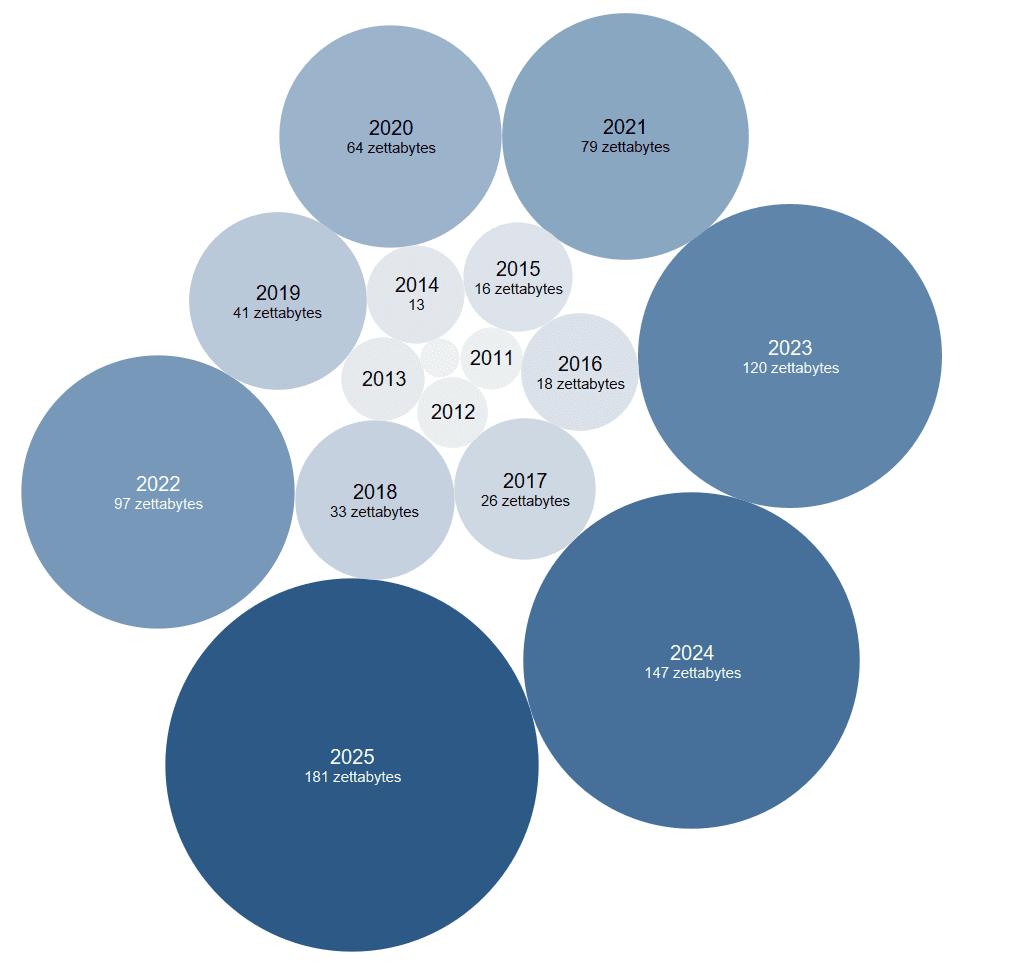
Note: To give an idea of the scale and size of this data, let's think in terms of floppy disks (popular from around 1970 to 2000). Each disk is pretty small and could hold around one Megabyte of data. To hold one Gigabyte of data, you would need around 715 floppy disks, which would stack up to 1.2 times the height of Usain Bolt. If you increase to one Terabyte, this would equal three times the height of the Burj Khalifa. Finally, a Petabyte would take the return trip to London from Barcelona (so a Zettabyte is even more mind boggling).
Source: Compass Lexecon analysis based on data from Statista (https://www.statista.com/statistics/871513/worldwide-data-created/).
As a result, it is natural that increasingly large amounts of data trickle through to competition cases. As firms engaging in competition proceedings both generate and store more data (especially in cases related to technology industries), larger volumes of data need to be analysed in order to answer questions of interest. For economic consultants and data scientists conducting the analysis, it is essential that the skills and technologies we employ are up to the task.
The “old way” of storing this information locally on laptops or even local servers often proves challenging as these cannot handle the vast amounts of data we receive in some projects, which has meant scaling up our data storage capabilities.
On top of storing this data efficiently, we also need to perform robust and timely analyses. This means that we have needed to leverage advancements in data processing technologies (e.g., cloud-based distributed analysis platforms). Despite the challenges, the world of big data presents exciting opportunities for data scientists and economists to apply their expertise.
In the article, we discuss how all of this impacts our daily work, along with some examples of tools we have used to help us deal with the challenges of working with larger data.
Technology is (and has been) evolving drastically
In the past, economists have mostly used data stored in so-called “flat files”, like those in Excel, to conduct our analyses (perhaps then importing them into a statistical analysis software such as Stata or R). This works well for small data. However, as the volume of data in these files increases, there comes a point where performing analysis means unsatisfactorily long processing times (at a certain scale, this would preclude running analyses altogether).
To respond to this, we have deployed several tools that allow us to run our analyses in a timely manner regardless of the volume of data involved.
Database technology is designed to allow users to efficiently store, query and share large datasets, and is almost always the preferred approach compared to using flat files. This is because databases are much faster and are better at handling large data volumes. This brings significant time savings to proceedings and can significantly reduce costs for our clients.
The illustration below shows two attempts at making the same chart. The left-hand side shows an attempt to build a chart linking a medium sized Excel file and the right-hand side shows it with the data queried from a database. As you can see, the version on the right has a chart almost ready in less than 20 seconds, whilst the Excel version is still stuck with the message showing “Loading data for preview…”.
Figure 2: Illustration of CSV versus SQL (one of the large database tools)
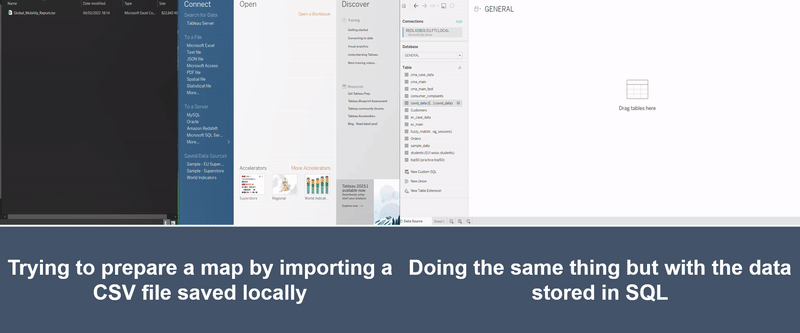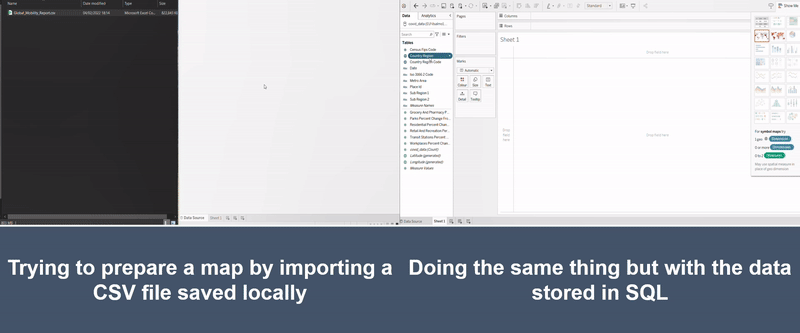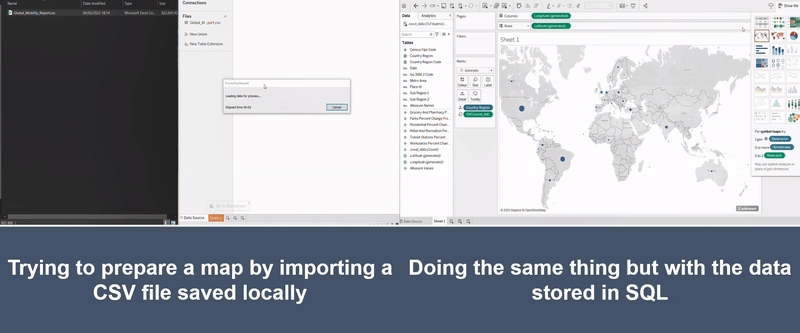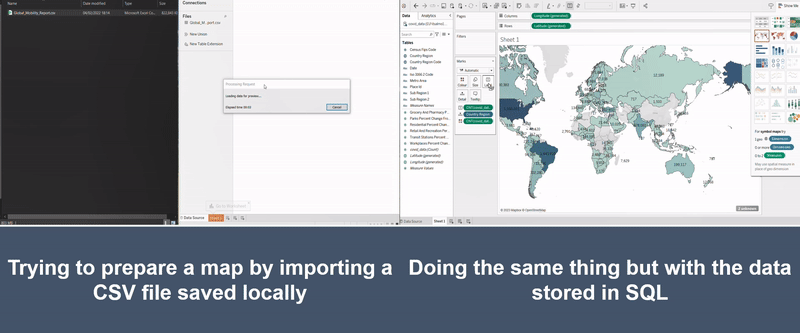
Note: It did however take the authors a disturbing amount of time to make the GIF illustrating how much time these tools can save.
Database management systems – which typically use “structured query language” (SQL) technology – have been an integral part of Compass Lexecon’s toolkit in managing large datasets. We have deployed several database servers within our systems and have built out tools that allow our economists to easily and securely upload client data and start processing it at high speed.
As datasets become even larger (i.e., they become much larger than one or two terabytes), and sophisticated, “on-premise” database servers of the kind deployed at Compass Lexecon can become insufficient. For such “big data”, we instead leverage databases hosted on cloud platforms, like Microsoft Azure. The benefit of cloud platforms is that scaling – i.e. increasing database size and performance in response to needs – is virtually effortless, meaning that regardless of the size of data we receive from our clients, we are able to quickly and effectively process it. While it is relatively effortless, larger servers have increasing costs and making the appropriate speed/cost trade-off is often critical.
What this means for our day-to-day
Technology is a tool, not a solution. It is ultimately up to our economists and data scientists to use these data storage and analytics tools effectively to reap the benefits in our projects or case work. To optimise the use of these tools, we have been developing best practices and standards to manage large datasets. This involves two key components: 1) ensuring the necessary infrastructure is in place so we can host the data in one format or another, depending on the case specifics, and 2) imparting the relevant knowledge to everyone in the firm to ensure these tools are used safely and efficiently.
Our data science team is skilled to leverage the technology and know-how to conduct economic and econometric studies effectively on large sets of data. For example, we have used this technology on our projects:
Typically, data transfer from clients to economic consultants is a major bottleneck in cases with tight deadlines, as it involves frequent data extraction requests and counsel needing to process these requests. In recent cases, we have moved to a model where our clients host data on their server, which we connect to and access directly. This allows us to understand the client’s data in its entirety, reducing the burden on counsel and the client. This also enables us to fully verify the extraction process and avoid unexpected circumstances due to misunderstandings or miscommunication. In several other cases, datasets ranging from five to hundreds of GBs were provided to us from a variety of different sources. To handle these, we prepared code to organise, process, and upload the data into a large dataset tool. This provides a central “source of truth” for us to organise, manage, and query the data, and ensure that all subsequent analysis is done quickly, with no errors.Conclusion: Looking ahead

Source: Tweet from Marc Benioff (CEO of Salesforce)
In this Data Science article, we discussed our expertise in handling large amounts of data. This is an ongoing process that we continue to improve on as the amount of data we work with keeps increasing, and the technologies that are available in the market keep improving. By tackling the obstacles head-on, we develop innovative solutions and methodologies to harness the power of big data, transforming raw information into valuable knowledge that informs strategic decisions.
We have only considered the more technical side of hosting larger datasets in this article. By enabling the ability to host and work with bigger and more complex datasets, this opens doors for more sophisticated analyses, whether it relates to natural language processing, applications of machine learning for prediction or causal inference, or the analysis of algorithms.
About the Data Science Team
The Compass Lexecon Data Science team was created to bring the latest developments in programming, machine learning and data analysis to economic consulting.
Sometimes this involves applying novel techniques to assess specific questions in an innovative and compelling way. For instance, running a sentiment analysis on social media content related to merging firms can be informative on their closeness of competition, and can supplement the results of a survey.
Other times it is about making work faster, more accurate, and more efficient, especially on cases which involve large datasets.
This short article is part of a series of articles showcasing how data science can lead to more streamlined and robust economic analysis and ultimately to better decisions in competition cases. If you would like to find out more, please do not hesitate to contact us at datascience@compasslexecon.com.
[1] With many thanks to Michael Sabor, Rashid Muhamedrahimov, Joe Perkins, Wiktor Owczarz and Antoine Victoria for their comments and suggestions. The views expressed are those of the authors only and do not necessarily represent the views of Compass Lexecon, its management, its subsidiaries, its affiliates, its employees, or clients.
Related insights
-

Article • 22 Feb 2023
A taste of geospatial analysis for competition economics
-
Article • 07 Dec 2022
Decision Search Tool: Behind the Scenes
-
Article • 21 Sept 2022
Measuring of Competition Using Natural Language Processing


