The privacy paradox: how much do social network users value their data?

Share
There is an apparent tension between how much individuals say they value privacy and how freely they provide their personal data to online services and platforms. This so-called privacy paradox has bothered policymakers for years, often justifying inaction. Patricia Lorenzo and Alejandro Requejo describe why it exists, how it can be solved, and how much consumers really value their data.
The views expressed in this article are the views of the authors only and do not necessarily represent the views of Compass Lexecon, its management, its subsidiaries, its affiliates, its employees or its clients.
The value of data to businesses
Consumers’ data is valuable. Currently, the most valuable companies in the world, Google, Apple, Facebook, Amazon, and Microsoft rely on business models for which data is an important driver of their value propositions. Firms like Google and social networks, such as Facebook, collect data about their users – such as their browsing patterns, shopping preferences and even, sometimes, social interactions – in order to sell targeted advertising space to their clients. Online retailers, such as Amazon, collect data about their customers in order to learn about their preferences and enhance their product offerings to users.
Data is not only valuable to the Big Tech giants. There is also a broad range of companies of all sizes whose business models rely on the collection, processing, and/or dissemination of data, such as, data brokers, app developers, and data security providers. It was estimated that at the end of 2020 in Europe the data industry would be worth around 740 billion euros and would employ 10.4 million workers.[2]
The paradoxical value of data to consumers
Undoubtedly, consumers have shared the value generated from their data. Myriad valuable services such as search engines, instant messaging or online video services are directly available free of financial payment to anyone with internet access (which is nearly 60% of the world population in 2020). Additionally, by gathering information from consumers, firms can learn about their preferences and therefore offer to them, or even develop for them, better (targeted) products and services.
However, the growth of the digital economy has been accompanied by increasing privacy concerns. Firstly, internet users worry about data breaches and misuse of their personal data. Secondly, harnessing personal data may allow firms to price discriminate – charging different customers different prices for the same product or service according to data revealing the maximum amount each of them is willing to pay. Firms may thus extract more of the economic rents for themselves at the expense of consumers.
Academic research has found what appears to be an inconsistency between how much individuals say they value privacy and how freely they provide their personal data – the so-called privacy paradox.[3] When asked about protecting their privacy, respondents tend to put a high value on their personal data, yet, arguably, their observed behavior indicates otherwise: many people seem willing to trade their personal data for very little in exchange and seem unwilling to employ available technology that is capable of protecting their privacy.
However, supporters of privacy public policy protection deny the so-called privacy paradox. They claim that the true valuation of privacy cannot be accurately inferred from an individual’s actions since those choices are driven by behavioral biases. Users’ decisions are conditioned by what they understand about the information they give up in exchange for services. The apparent paradox may simply indicate that consumers are providing more data than they intend to, or would choose to if they were fully informed. Certainly, many internet users do not fully understand how much data is being collected from them and for what purpose. Consumers are rarely informed in all detail about how their data might be used or shared with third parties. Or they may rationally choose not to pay attention, given the complexity of accurately assessing the costs and benefits of their actions. There is evidence that most customers do not read privacy policies. And if they do, they do not fully understand them.
From a policy perspective, it is important that we can answer questions such as: “how much does data privacy really matter to consumers?” or “to what extent are consumers willing to trade off their privacy for better services, such as targeted advertising, and in what ways?” Without a rigorous way to address those questions we can’t meaningfully consider consumers’ interests in either direction.
In this article we explain how survey data can be used to answer those questions. Specifically, we explain how to use ‘choice modelling’ to reliably estimate whether users value their privacy and how much they do so when interacting with social networks. We illustrate the power of this approach by describing the main results of a recent survey on a sample of German social network users. Those results show what uses of their data well-informed social network users were willing to accept, in exchange for either monetary incentives or better-quality targeted advertisements.[4]
How survey data can be used to estimate how much consumers value privacy
We can use survey data to understand to what extent consumers value their privacy. In particular, choice modelling is a survey-research methodology that has become very popular in economic and marketing literature. This methodology has been widely used in practice and has been proven to aid decision-making in the design of optimal pricing policies, valuation of intellectual property rights, estimation of demand for new services, and the definition of relevant markets, amongst other uses.
Choice modelling techniques require information on decisions made by consumers and the factors that can influence these decisions. This information is typically collected through surveys that simulate decisions made by individuals (or companies). Consumers’ decisions usually consist of a choice made from a finite set of alternatives, where each one offers a different set of attributes. For example, consumers would choose between different social networks depending on the attributes they offered, such as the type of data each would collect (e.g. personal data, non-personal data, location data), the type of data each would sell to third parties (e.g. aggregated vs disaggregated data), the type of targeted advertisement each offers (e.g. low quality vs. high quality ads), and the monetary incentives (if any) each offers to users where the social network pays the consumer for greater access to their data).
Simulating consumers’ decisions is important because – unlike our observations of choices in the real world – it allows us to identify and control the circumstances that condition consumers’ choices. Firstly, we can test whether consumers understand the choices in front of them and ensure that they do. Secondly, we can present consumers with new sets of options that might not be available in the real world. That enables us to better understand their preferences (which is why this technique is so popular in marketing exercises). With this level of control, we can avoid the behavioral biases that affect the choices we observe in the market.
A recent survey of German social network users’ preferences
We have recently used choice modelling to estimate German social network users’ willingness to accept the use of their data in exchange for better-targeted advertisement, or monetary payment.[5]
When doing an exercise of this nature there are several decisions to be made:
- Willingness to Pay vs Willingness to Accept: some of the existing studies in the economic literature have focused on estimating consumers’ willingness to pay (WTP) to ensure privacy.[6] However, experimental evidence indicates that consumers’ WTP is significantly below their willingness to accept (WTA), which is the lowest price that a consumer would accept in exchange for revealing private data.[7] Thus, it follows that estimates of the value of privacy based on consumers’ WTP may be biased downwards. Because of these limitations when applying those techniques to a sample of German social network users we have estimated users’ WTA.
- Contingent valuation vs Choice modelling: broadly, there are two survey approaches, “contingent valuation” and choice modelling. Contingent valuation survey methods directly ask consumers (or respondents) how much they are willing to pay (or accept) for a given service or product. The reliability of the answers to direct questions is limited. For example, respondents often claim to be much more responsive than they truly are in order not to appear stupid to the interviewer. Other respondents may answer strategically to the survey’s questions. Even when they answer candidly, their responses may not serve to elicit their true preferences because they may be conditioned by the way the questions are posed, the set of possible answers may be constrained, or the questions impose answers that are vague, unrealistic, or drastic. It is common knowledge that discrete choice modelling analyses are superior to contingency surveys because they are less vulnerable to the problems described above.[8] In particular, the survey environment of these methodologies is designed to resemble the real decision-making situation as closely as possible. The work we conducted is based on discrete-choice experiments.
Our target population comprises German residents, aged 16 to 74 years, who used social networks within the 3 months before they were interviewed.[9] The final sample consisted of 1,002 interviews and was randomly selected from a panel that is representative of the German population in terms of different socio-demographic criteria (e.g., gender, age, and geographical representativeness).
The survey included (a) an initial questionnaire about the respondents’ socio-demographic characteristics, their use of social networks, and their knowledge of how social networks collect and use their data; and (b) a series of choice experiments, where respondents had to choose among various social networks differing, among other things, on the nature and amount of data collected, the uses given to such data, the quality of the ads being shown, and the amount of money respondents would be paid for their data.
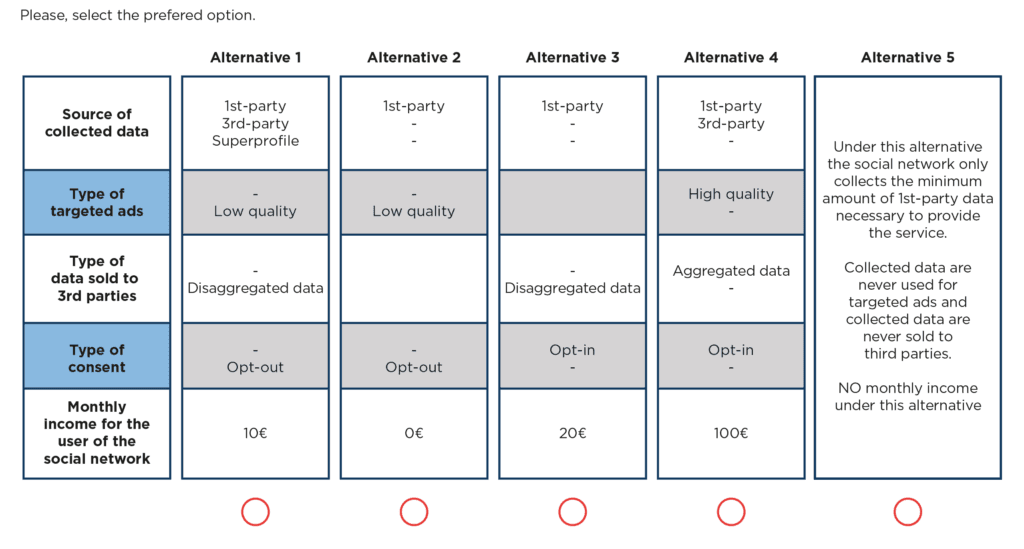
In the choice exercise, respondents were presented with five alternatives and they were asked to select their most preferred one (see Figure 1 below).[10]
The first four alternatives were characterized by the following attributes.
- The type of data collected by the network: the network may collect first-party data (i.e. data from the network itself), third-party data (e.g. data from other online platforms), or first- and third-party data. The network may combine the first-party and third-party data it collects to create user super-profiles.
- The type of targeted ads: the network may offer no targeted ads, low-quality targeted ads, or high-quality targeted ads.
- The type of data sold to third parties: the network may not sell data to third parties, sell data in an aggregated way (so that no individual can be identified) or disaggregated data.
- The type of consensus: users may be given the ability to opt-out of the data collection or, alternatively, the possibility of opting in.
- The scale of monetary incentive to provide data: the social network could pay their users a monthly fee ranging between 5 to 100 euros in exchange for their data, or, alternatively, not pay them at all for network use.
The questionnaire included detailed definitions of all these attributes and respondents were asked to answer a series of verification questions before undertaking the choice exercises to confirm that they had understood all those definitions. Unlike observations of real-world choices, this ensured consumers’ decisions indicated their true preferences.
Each set of choices contained a ‘fifth alternative’, in which:
- the social network only collects first-party data necessary to provide its network services, which are the same quality as those provided by the alternative networks;
- data collected are not used for the delivery of targeted ads and/or sold to third parties; and
- the network does not pay monetary incentives.
Figure 1: Example of choice experiment used in the German study
Respondents were asked to undertake several choice experiments. Both the initial questionnaire and the choice experiments were answered online, and respondents had no time limit to provide their answers.
The choice modelling methodology we used (the so-called “mixed logit” model) allows preferences to vary between consumers and so accounts for the potential heterogeneity of respondents’ preferences. Respondents were asked to undertake several choice experiments. Both the initial questionnaire and the choice experiments were answered online, and respondents had no time limit to provide their answers.
What did the study reveal?
The study confirmed that consumers use social networks without fully understanding what data they provide in exchange, or for what purpose.
- Most respondents used social networks daily, they used more than one social network and were particularly keen on Facebook and Instagram, and they spent less than one hour per day on their most preferred network.
- Many respondents were unaware of the data collection, data processing, and data commercialization strategies of the social networks they relied upon. Only 32% declared awareness of all the above.
- Most respondents declared not to have read the Terms and Conditions of the social network they used most. About 10% read them but did not understand them. Only 16.9% had read them and understood them before signing up with their preferred network. And only 15.7% of respondents declared that they read the social network’s Terms of Service and Data Policy after signing up.
- Respondents placed significant value on their data and privacy. The results of the choice experiment show how much money users required before they were willing to accept different uses of their data. The average respondent demands:
- 15 euros per month if the social network collects third-party data and not only first-party data;
- 51 euros per month if the social network uses first- and third-party data to create user super-profiles;
- 80 euros per month if the social network displays low quality targeted ads;
- 78 euros per month if the social network sells disaggregated data to third parties; and
- 37 euros per month if the social network sells aggregated data to third parties.
Additionally, the average respondent is indifferent between a social network that only collects and sells data if users “opt-in” and another one where data is collected and sold unless users “opt-out”.
They are also indifferent between a social network that displays high-quality targeted ads and one that does not display any ads – meaning that targeted ads do not compensate consumers for the cost of their data.
Finally, we have used the results from the choice exercise to estimate how much respondents value their privacy. We analyzed the monetary incentive that would make the average consumer indifferent between (a) a social network that does not collect data, does not display targeted ads, nor sells data to third parties (i.e., the “5th alternative” that respondents could choose) and (b) a network that collects first- and third-party data, creates user super-profiles, displays low quality targeted ads, sells disaggregated data to third parties, and in which users only have the right to opt-out (“social network 1”).
The average respondent was only willing to accept “social network 1” in exchange for 150.38 euros per month. When social network 1 offers less, the average respondent would rather choose the “5th alternative” – i.e., a social network with untargeted advertising, not informed by their data. This preference is widespread. More than 90% of respondents require a positive monetary incentive each month to be indifferent between the two abovementioned networks.
Our findings confirm the intuitions developed by previous studies showing that users of social networks dislike targeted advertising, especially low-quality targeted ads.[11] Also, like previous studies, our choice modelling exercise shows that social network users are unwilling to trade off privacy for targeted advertising.[12]
[1] The views expressed in this article are the views of authors only and do not necessarily represent the views of Compass Lexecon, its management, its subsidiaries, its affiliates, its employees, or its clients. This article is based upon Lorenzo, Patricia and Padilla, Jorge and Requejo, Alejandro, Consumer Preferences for Personal Data Protection in Social Networks: A Choice Modelling Exercise (October 21, 2020). Available at SSRN: https://ssrn.com/abstract=3716206 or http://dx.doi.org/10.2139/ssrn.3716206. That analysis was commissioned by The British Institute of International and Comparative Law.
[2] See European Commission (2017), The European Data Market Study: Final Report, available at http://datalandscape.eu/study-reports/european-data-market-study-final-report, last accessed on April 29, 2020. See here for update: https://datalandscape.eu/sites/default/files/report/D2.9_EDM_Final_study_report_16.06.2020_IDC_pdf.pdf
[3] See Acquisti, A., Taylor, C. and Wagman, L., (2016), “The Economics of Privacy,” Journal of Economic Literature, Vol. 54(2), pp. 442—492, and references therein.
[4] Lorenzo, Patricia and Padilla, Jorge and Requejo, Alejandro, Consumer Preferences for Personal Data Protection in Social Networks: A Choice Modelling Exercise (October 21, 2020). Available at SSRN: https://ssrn.com/abstract=3716206 or http://dx.doi.org/10.2139/ssrn.3716206.
[5] Íbid.
[6] See for instance Winegar and Sunstein, (2019), “How Much Is Data Privacy Worth? A Preliminary Investigation”, Journal of Consumer Policy, forthcoming.
[7] See e.g. Grossklags, J. and Acquisti, A. (2007), “When 25 cents Is Too Much: An Experiment on Willingness-To-Sell and Willingness-To-Protect Personal Information.” In Workshop on Economics of Information Security, Pittsburgh.
[8] See Diamond, P.A., and Hausman, J.A., (1994), “Contingent Valuation: Is Some Number Better than No Number?” Journal of Economic Perspectives, Vol. 8 (4), pp. 45-64 and Hausman, J.A. (2012), “Contingent valuation: from dubious to hopeless”, The Journal of Economic Perspectives, 26(4), 43-56.
[9] See Lorenzo, P. and Padilla, J. and Requejo, A. (2020), op. cit.
[10] We optimally designed 100 different sets with combinations of 5 alternatives with different combinations of attributes, designed using the general method for efficient choice designs (“ChoiceEff” SAS macro) developed by Zwerina et. Al. (2005). Each respondent faced 5 out of these 100 different sets. Specifically, they were asked to select their most preferred alternative for each of these 5 sets. Zwerina, K., Huber, J. and Kuhfeld W.F. (2005), “A General Method for Constructing Efficient Choice Designs”, SAS Technical Papers, available at http://support.sas.com/techsup/technote/mr2010e.pdf.
[11] See for instance, Johnson, J. P. (2013): “Targeted advertising and advertising avoidance.” RAND Journal of Economics, Vol. 44 n°1, pp. 128-144 or Pepall, L. and Reiff, J. (2016), “The “Veblen” Effect, Targeted Advertising and Consumer Welfare.” Economics Letters 145, pp. 218-220.
[12] See for instance John, L. K., Kim, T. and Barasz, K. (2018), “Ads That Don’t Overstep”. Harvard Business Review, Jan-Feb 2018.
Related insights
-

Article • 17 Aug 2021
Q&A: Competition and antitrust issues in digital markets

{kind=link}